University of Alberta, Edmonton, June 8th & 13th 2015
Sjur Moshagen, UiT The Arctic University of Norway
Edmonton presentation
Overview of the presentation
Overview of the presentation
background and goals
bird's eye view
closer view of selected parts:
documentation
testing
from source to final tool
Edmonton presentation
Background and goals
Background and goals
Background
Goals
Edmonton presentation
Background and goals
Background
Background
need for simpler maintenance
scalability, both for languages, tools and linguists and other developers
developing NLP resources is a lot of work, and languages are complex - we need a tool and an infrastructure to handle the complexity in a managable way
keep technical details out of the way
make the daily work as simple as possible
division of labour
Recognition: know the basic setup of one language - know the setup of them all
Edmonton presentation
Background and goals
Goals
Goals
easy support for many languages
easy support for many tools
keep language independent and language specific code apart
easily upgradable
the resources in our infrastructure should live on for decades or more
Edmonton presentation
Background and goals
General principles
General principles
Be explicit (use non-cryptic catalogue and file names)
Be clear (files should be found in non-surprising locations)
Be consistent (identical conventions in all languages as far as possible)
Be modular
Divide language-dependent and language-independent code
Reuse resources
Build all tools for all languages
... but only as much as you want (parametrised build process)
Edmonton presentation
Bird's Eye View and Down
Bird's Eye View and Down
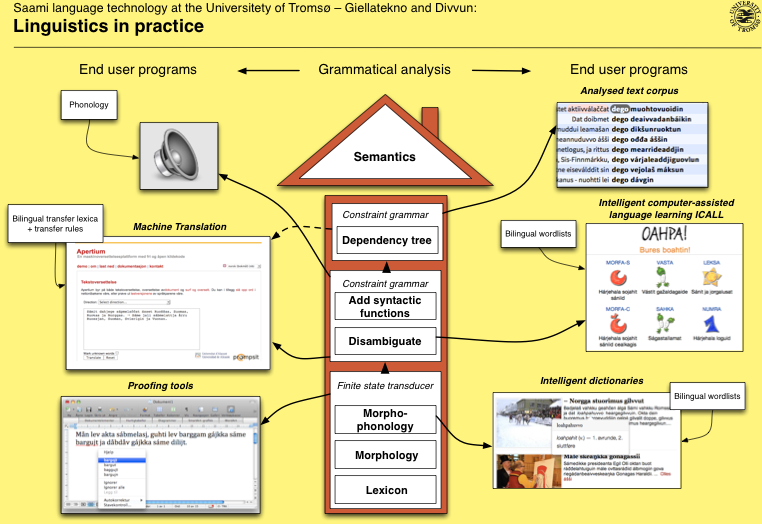
the house
organisation - directory structure
technologies (xerox, hfst, foma + cg)
templated build structure and source files
configuration of builds
Edmonton presentation
Bird's Eye View and Down
The House
The House
Edmonton presentation
Bird's Eye View and Down
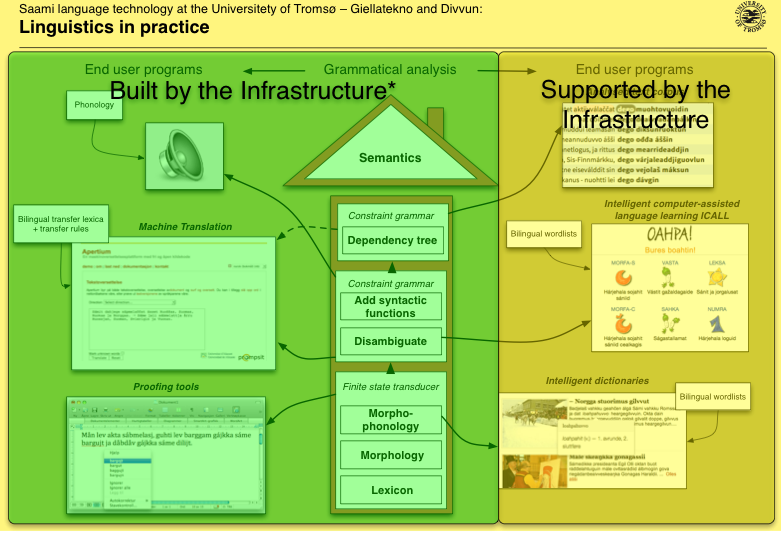
The House and the Infra
The House and the Infra
*Machine translation: fst's built by the infra, the rest handled by Apertium
*Speech synthesis is not (yet) built by the infra, conversion to IPA is part of the infrastructure though
Supported: fst's and syntactic parsers used are built by the infrastructure
Edmonton presentation
Bird's Eye View and Down
$GTHOME - directory structure
$GTHOME - directory structure
Some less relevant dirs removed for clarity:
$GTHOME/ # root directory, can be named whatever
├── experiment-langs # language dirs used for experimentation
├── giella-core # $GTCORE - core utilities
├── giella-shared # shared linguistic resources
├── giella-templates # templates for maintaining the infrastructure
├── keyboards # keyboard apps organised roughly as the language dirs
├── langs # The languages being actively developed, such as:
│ ├─[...] #
│ ├── crk # Plains Cree
│ ├── est # Estonian
│ ├── evn # Evenki
│ ├── fao # Faroese
│ ├── fin # Finnish
│ ├── fkv # Kven
│ ├── hdn # Northern Haida
│ └─[...] #
├── ped # Oahpa etc.
├── prooftools # Libraries and installers for spellers and the like
├── startup-langs # Directory for languages in their start-up phase
├── techdoc # technical documentation
├── words # dictionary sources
└── xtdoc # external (user) documentation & web pages
Edmonton presentation
Bird's Eye View and Down
Organisation - Dir Structure
Organisation - Dir Structure
.
├── src = source files
│ ├── filters = adjust fst's for special purposes
│ ├── hyphenation = nikîpakwâtik > ni-kî-pa-kwâ-tik
│ ├── morphology =
│ │ ├── affixes = prefixes, suffixes
│ │ └── stems = lexical entries
│ ├── orthography = latin -> syllabics, spellrelax
│ ├── phonetics = conversion to IPA
│ ├── phonology = morphophonological rules
│ ├── syntax = disambiguation, synt. functions, dependency
│ ├── tagsets = get your tags as you want them
│ └── transcriptions = convert number expressions to text or v.v.
├── test =
│ ├── data = test data
│ └── src = tests for the fst's in the src/ dir
└── tools =
├── grammarcheckers = prototype work, only SME for now
├── mt = machine translation
│ └── apertium = ... for certain MT platforms
├── preprocess = split text in sentences and words
└── spellcheckers = spell checkers are built here
Edmonton presentation
Bird's Eye View and Down
Technologies
Technologies
All technologies are rule-based as opposed to statistical and similar technologies.
This allows us to write grammars that are precise descriptions of the languages - reference grammars in a way
Goal: The documentation for your grammar - with suitable examples etc - could be the next published grammar for your language (we'll return to thatshortly)
Edmonton presentation
Bird's Eye View and Down
Technologies
Technology for morphological analysis
Technology for morphological analysis
We presently use three different technologies:
Xerox - closed source, not properly maintained, fast, no weights
Hfst - open source, actively maintained, used in our proofing tools
Foma - Open source, actively maintained, fast (newly added, not availablefor all fst's yet)
Edmonton presentation
Bird's Eye View and Down
Technologies
Technology for syntactic parsing
Technology for syntactic parsing
Cg (VISLCG3, from University of Southern Denmark)
used for syntactic parsing
also for grammar checking
Basic idea: remove unwanted readings or select wanted ones based on the morphosyntactic context (= output of the morphological analysis)
Example:
# We like finite verbs:
SELECT:Vfin VFIN ;
Edmonton presentation
Bird's Eye View and Down
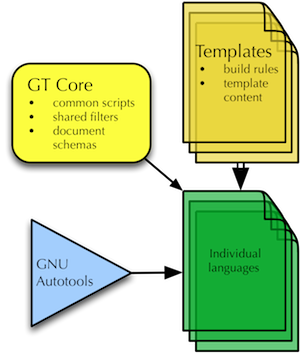
Templated Build Structure And Source Files
Templated Build Structure And Source Files
Common resources in $GTHOME/core/
Template for new languages, including build instructions
The template is merged (using svn merge) with each language when updated
Edmonton presentation
Bird's Eye View and Down
Configurable builds
Configurable builds
We support a lot of different tools and targets, but in most cases one only wants a handful of them. When running ./configure, you get a summary of the things that are turned on and off at the end:
$ ./configure --with-hfst
[...]
-- Building giella-crk 20110617:
-- Fst build tools: Xerox, Hfst or Foma - at least one must be installed
-- Xerox is default on, the others off unless they are the only one present --
* build Xerox fst's: yes
* build HFST fst's: yes
* build Foma fst's: no
-- basic packages (on by default): --
* analysers enabled: yes
* generators enabled: yes
* transcriptors enabled: yes
* syntactic tools enabled: yes
* yaml tests enabled: yes
* generated documentation enabled: yes
-- proofing tools (off by default): --
* spellers enabled: no
* hfst speller fst's enabled: no
* foma speller enabled: no
* hunspell generation enabled: no
* fst hyphenator enabled: no
* grammar checker enabled: no
-- specialised fst's (off by default): --
* phonetic/IPA conversion enabled: no
* dictionary fst's enabled: no
* Oahpa transducers enabled: no
* L2 analyser: no
* downcase error analyser: no
* Apertium transducers enabled: no
* Generate abbr.txt: no
For more ./configure options, run ./configure --help
Edmonton presentation
Bird's Eye View and Down
The build - schematic
The build - schematic
Edmonton presentation
Closer View Of Selected Parts:
Closer View Of Selected Parts:
Documentation
Testing
From Source To Final Tool:
Relation Between Lexicon, Build And Speller
Edmonton presentation
Closer View: Documentation
Closer View: Documentation
Background
Implementation
Edmonton presentation
Closer View: Documentation
Background
Background
Documentation is always out-of-date
It tends to be much more out-of-date when heavily separated from the thing to be documented, and vice versa
How to improve: make it possible to write documentation within the source code
This is similar to JavaDoc, Doxygen and many other such system
Ultimate goal:
Document the source code so that it can be published as the next reference grammar!
Edmonton presentation
Closer View: Documentation
Implementation
Implementation
The infrastructure will automatically extract comments of a certain type, and convert them into html
One can cite portions of the source code, as well as test data.
The syntax of the comments must follow the jspwiki syntax
each yaml test file has its own line of output with PASS / FAIL /TOTAL
at the end of each yaml test run (= all yaml files for the same fst) thereis a summary of the total results for that yaml test run
... followed by the Automake PASS / FAIL message
Edmonton presentation
Closer View: Testing
In-Source Tests
In-Source Tests
LexC tests
Twolc tests
Edmonton presentation
Closer View: Testing
In-Source Tests
LexC tests
LexC tests
As an alternative to the yaml tests, one can specify similar test data within the source files:
LEXICON MUORRA !!= @CODE@ Standard even stems with cg (note Q1). OBS: Nouns with invisible 3>2 cg (as bus'sa) go to this lexicon.
+N: MUORRAInfl ;
+N:%> MUORRACmp ;
!!€gt-norm: kárta # Even-syllable test
!!€ kártta: kártta+N+Sg+Nom
!!€ kártajn: kártta+N+Sg+Com
Such tests are very useful to serve as checks for whether an inflectional lexicon behaves as it should.
The syntax is slightly different from the yaml files:
The point is to ensure that the rules behave as they should.
Edmonton presentation
Closer View: Testing
Other Tests
Other Tests
You can write any test you want, using your favourite programming language. There are a number of shell scripts to test speller functionality, and more tests will be added as the infrastructre develops.
Edmonton presentation
Closer View: From Source To Final Tool:
Closer View: From Source To Final Tool:
Relation Between Lexicon, Build And Speller
Fst's And Dictionaries
Edmonton presentation
Closer View: From Source To Final Tool:
Relation Between Lexicon, Build And Speller
Relation Between Lexicon, Build And Speller
tag conventions
automatically generated filters
spellers and different writing system / alternative orthographies
Edmonton presentation
Closer View: From Source To Final Tool:
Relation Between Lexicon, Build And Speller
Tag Conventions
Tag Conventions
We use certain tag conventions in the infrastructure:
+Err/... ( +Err/Orth, +Err/Cmp)
+Sem/...
and more...
Edmonton presentation
Closer View: From Source To Final Tool:
Relation Between Lexicon, Build And Speller
Automatically Generated Filters
Automatically Generated Filters
Many of these clusters of tags are used for specific purposes, and are removed from other fst's.
tag using a common prefix (like +Err/ or +Sem/ gets filters for different purposes automatically
there are filers for:
removing the tags themselves
remvoing strings / words containing the tags
by adhering to these conventions, you get a lot of functionality for free
this system is used when...
Edmonton presentation
Closer View: From Source To Final Tool:
Relation Between Lexicon, Build And Speller
Dealing with descriptive vs normative grammars
Dealing with descriptive vs normative grammars
the normative is a subset of the descriptive
tag the non-normative forms using +Err/... tags
write your grammar as descriptive
remove the +Err/... strings
=> normative fst!
Edmonton presentation
Summary
Summary
scalability
division of labour
language independence
... but still flexible wrt the needs of each language