
ML Language Technology
Language technology for low-resource languages
Jack Rueter and Sjur Moshagen
Rule-based language technology
Our rule-based approach:
- two-level morphology (finite state transducers)
- disambiguation using Constraint Grammar
Both technologies developed here at HU : -)
Actual implementations:
- two-level morphology:
- Xerox XFST family (free, closed source)
- Hfst (free, open source)
- Foma (free, open source, no twolc compiler)
- Xerox XFST family (free, closed source)
- disambiguation and syntax:
- VISLCG3 (free, open source)
Open source is important, to avoid being locked in or spend much more money to
Word-level technology
- Morphophonology:
- twolc (a "variant" of SPE phonology)
- also rewrite rules ("real" SPE phonology)
- twolc (a "variant" of SPE phonology)
- Morphology: lexc
Both formalisms should be easily recognisable by linguists.
Example — twolc
Alphabet m p ; Rules "N:m rule" N:m <=> _ p: ; "p:m rule" p:m <=> :m _ ;
Target changes:
kaNpat kammat
Example — rewrite rules
The same changes written using rewrite rules:
[ N -> m || _ p ] .o. [ p -> m || m _ ];
Rewrite rules are ordered, twolc rules are not.
Example — lexc
A very simplistic English lexicon:
Multichar_Symbols
+V +Pres +3Sg +PresPtc +Past
! Lexicon containing lexical stems:
LEXICON Root
walk V ;
talk V ;
pack V ;
! Lexicon containing POS tag only:
LEXICON V
+V: V-suff ;
! Lexicon containing inflectional suffixes and corresponding tags:
LEXICON V-suff
+Pres+3Sg:s # ;
+Past:ed # ;
+PresPtc:ing # ;
+Pres: # ;
Summary
End result: computer model of morphology and morphophonology. This model can
Sentence level technology
VISLCG3, an extended version of the original Constraint Grammar syntax developed
Constraint grammars work "backwards": instead of imposing a structure on a
(a) REMOVE VFIN IF (-1 ART) ; (b) REMOVE (N) IF (-1 (PERS NOM)) ;
(a) will remove finite verb readings (the target) from a cohort, if the one
Note that the target VFIN is a defined set (e.g. consisting of tense or mode
Constraint grammars require a lot of manual work, but will generally achieve
Tools for linguistic research
- explicit grammars
- analysers
- generators
- analysed text
- try out different phonological models of a language
- use model to process (analyse) text
Explicit Grammars
- Writing for a computer forces you to be explicit about every aspect of the
- This can bring forth new areas of the grammar to research. Examples from the
- compounding
- derivations
- phonological alternations in Inari Sami
- North Sámi syntax
- compounding
Analysers
- morphological analysers can themselves be used as a tool for resarch (see
- a full-size lexicon can be used as source material for lexical research
Generators
- morphological generators will ruthlessly display all overgenerations, and thus
Use Model To Process (Analyse) Text
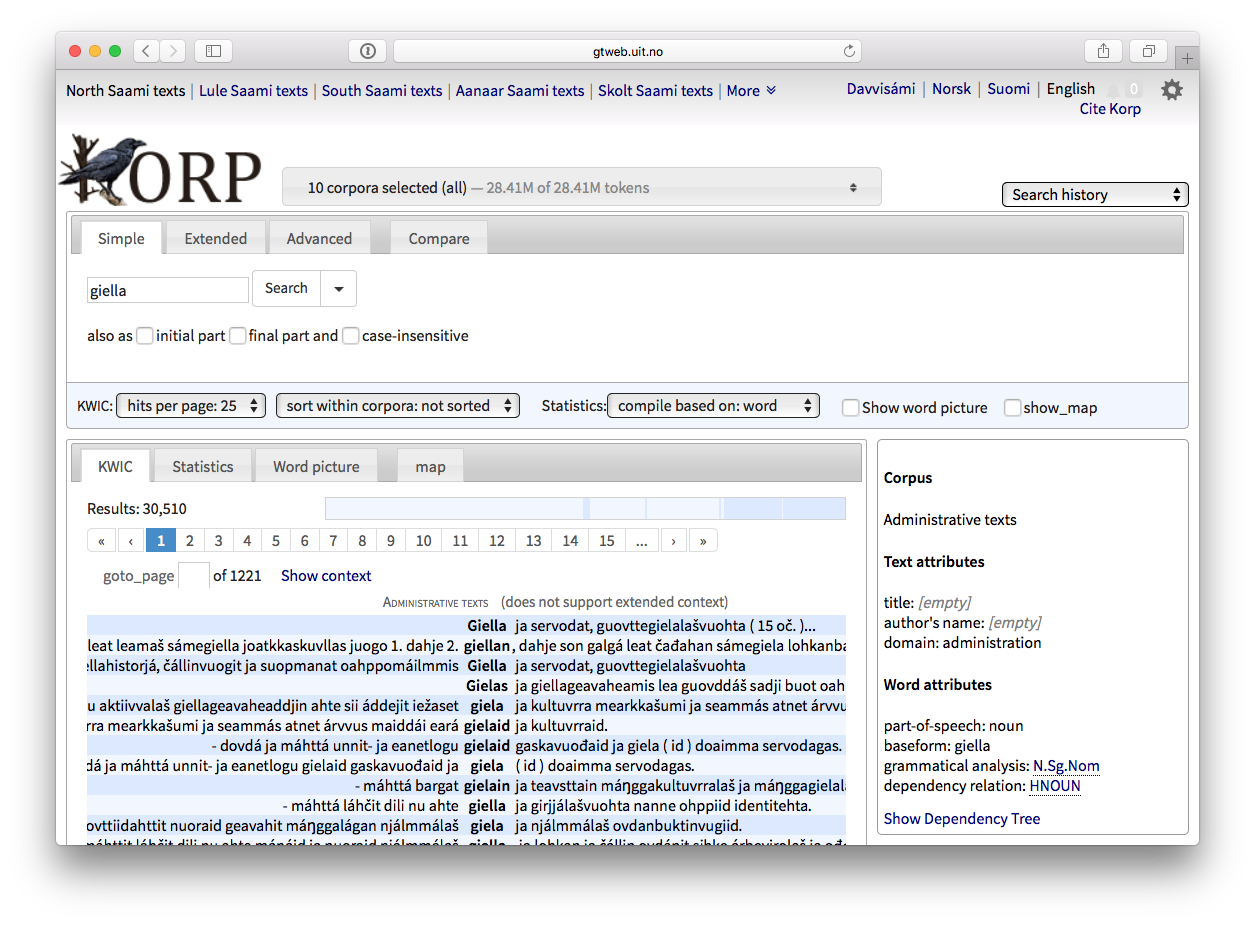
- The most important use of a morphological analyser is to analyse text.
=> Korp
Tools for speakers of minority languages
The listed tools are all supported by the Giella infrastructure.
- keyboards (desktop and mobile, soon with spellers)
- spell checkers
- morphologically aware hyphenators
- morphologically aware dictionaries
- grammar checkers
- Machine translation
- iCALL
- text-to-speech
Keyboards
- Desktop (Windows, macOS, Linux/X11)
- Mobile, soon with spellers
Without keyboards, writing texts in any language can become almost impossible.
Using the keyboard part of the Giella infrastructure,
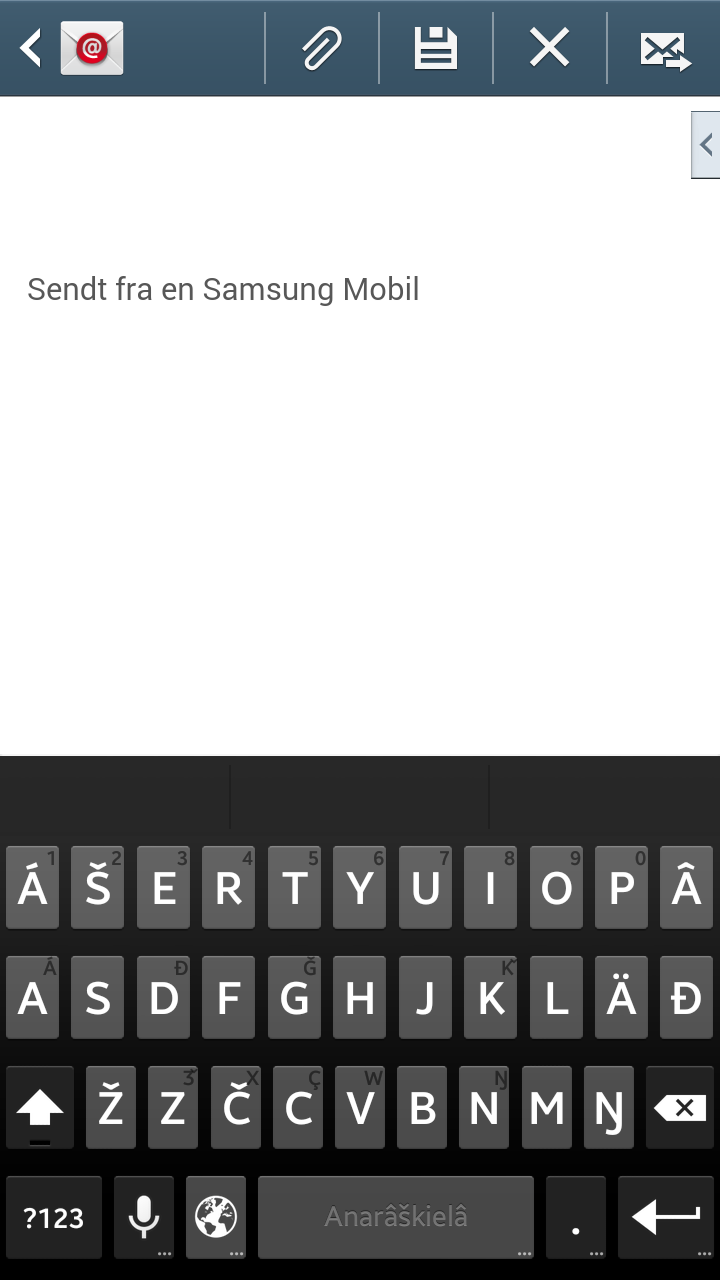
Layout definition
The layout definition is done using yaml syntax, and is just the following:
modes:
mobile-default: |
á š e r t y u i o p â
a s d f g h j k l ä đ
ž z č c v b n m ŋ
mobile-shift: |
Á Š E R T Y U I O P Â
A S D F G H J K L Ä Đ
Ž Z Č C V B N M Ŋ
longpress:
Á: Q
A: Å Á À Â Ã Ạ
á: q
a: å á à â ã ạ
(Demo: Skolt Sámi macOS keyboard)
Spell Checkers
- The next tool to develop is typically a spell checker.
- This is especially important for minority languages, because the minority
- The speller is essentially the lexical fst pluss an error model to create
- presently all spellers built using the Giella infrastructure is using Hfst
- every analyser can be turned into a speller in the Giella infrastructure,
- spellers are presently built for LibreOffice, and through an external service
- work is ongoing to build system-wide spellers for Windows, macOS and Linux
(Demo: gaelic)
Morphologically Aware Hyphenators
- especially important for compounding languages
- built just like spellers using the lexical fst, but such that word boundaries
Morphologically Aware Dictionaries
- if not making spellers first, then morphologically aware dictionaries is
- morphological analysis is used on the input to arrive at a list of lemma
- this is very important for languages with complex morphophonology or a lot of
Grammar Checkers
- the first grammar checker in the Giella infrastructure is being built now
- it uses a modified version of the morphological analyser together with
- at least the following error types are targeted in this first version:
- wrongly split compounds ("pika juna" vs "pikajuna")
- congruency errors
- real word errors
- wrongly split compounds ("pika juna" vs "pikajuna")
To handle wrongly split compounds, we convert word boundaries in compounds into
(Demo: grammar checker)
Machine translation
- morphological analysis -> disambiguation -> transfer dictionary -> lexical
- we use Apertium as our MT infrastructure
- analysers, generators and disambiguators are built in the Giella
- present target is:
- mainly related languages
- mainly understanding
- mainly related languages
- further ahead:
- better quality and coverage
- possibly near-production quality between near-related languages
- better quality and coverage
(Demo using Ávvir)
Icall
- language technology is used in several places to
- analyse student input
- analyse text to generate new excercises
- analyse student input
Text-To-Speech
- so far only one TTS system: North Sámi
- built using commercial and closed-source technology
- we want to replace as much as possible using open-source technology:
- text processing using Hfst and Vislcg3
- synthesis probably using the Festival system
- text processing using Hfst and Vislcg3
(Demo using Ávvir)
Conclusions
- The Giella infrastructure is targeted at low-resource and small language
- it supports building a number of essential tools for both research and the
- everything is open source as far as possible
- our infrastructure is just one of several, but it does showcase what is
- the decission to do everything rule-based is driven by three observations:
- with little data, current alternative technologies are not usable
- as long as there are speakers, there are language workers
- reuse is essential - one can not afford to do the same job multiple times
- with little data, current alternative technologies are not usable
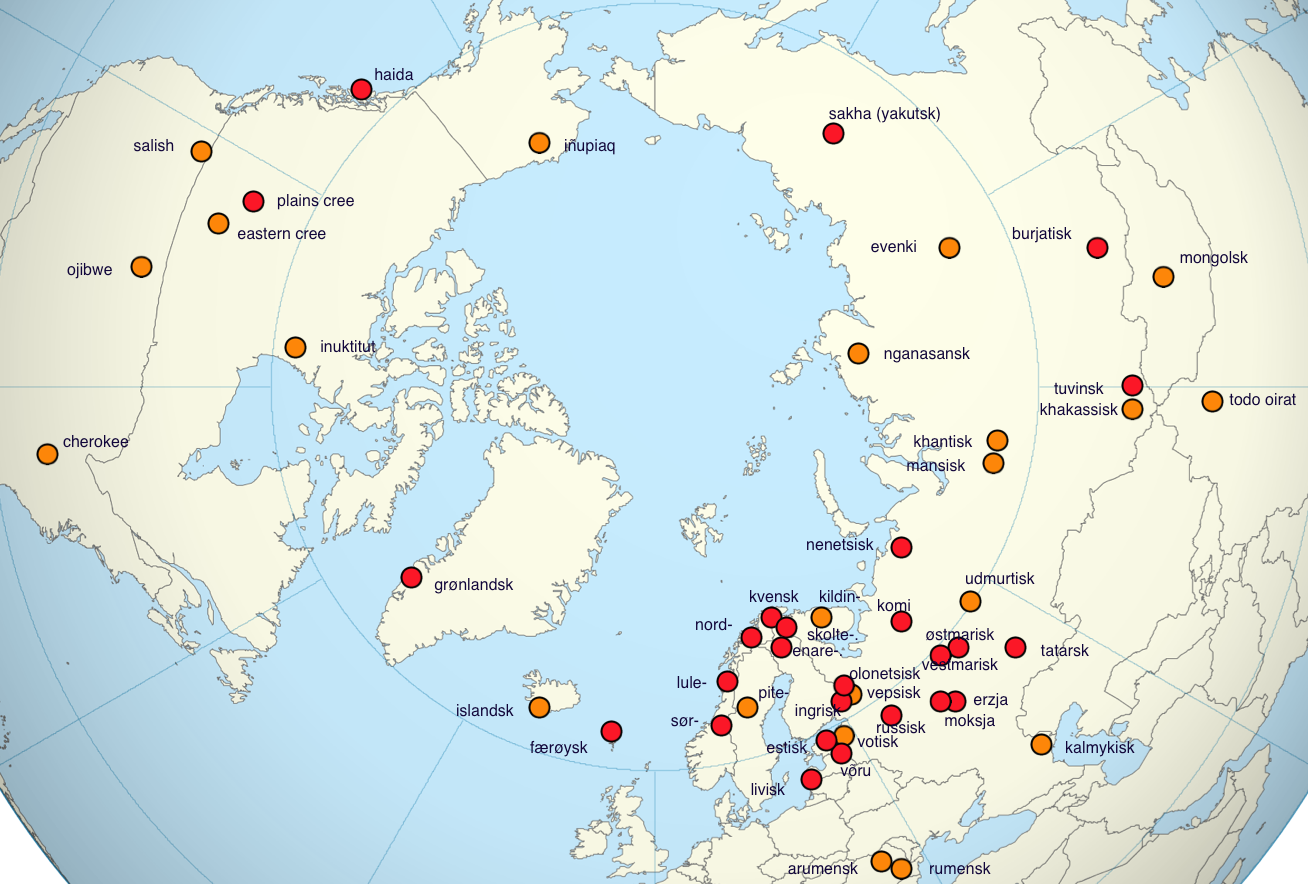
Language coverage
Hands-on on Thursday
- design a mobile keyboard
- add a word to the lexc source code, build a speller and test it in LO
- requires unix shell + some svn checkouts