
Edmonton Infrastructure Presentation2015
Edmonton presentation
University of Alberta, Edmonton, June 8th & 13th 2015
Sjur Moshagen, UiT The Arctic University of Norway
Overview of the presentation
- background and goals
- bird's eye view
- closer view of selected parts:
- documentation
- testing
- from source to final tool
- documentation
Background and goals
- Background
- Goals
Background
- need for simpler maintenance
- scalability, both for languages, tools and linguists and other developers
- developing NLP resources is a lot of work, and languages are complex - we need
- keep technical details out of the way
- make the daily work as simple as possible
- division of labour
- Recognition: know the basic setup of one language - know the setup of them all
Goals
- easy support for many languages
- easy support for many tools
- keep language independent and language specific code apart
- easily upgradable
- the resources in our infrastructure should live on for decades or more
General principles
- Be explicit (use non-cryptic catalogue and file names)
- Be clear (files should be found in non-surprising locations)
- Be consistent (identical conventions in all languages as far as possible)
- Be modular
- Divide language-dependent and language-independent code
- Reuse resources
- Build all tools for all languages
- ... but only as much as you want (parametrised build process)
Bird's Eye View and Down
- the house
- organisation - directory structure
- technologies (xerox, hfst, foma + cg)
- templated build structure and source files
- configuration of builds
The House
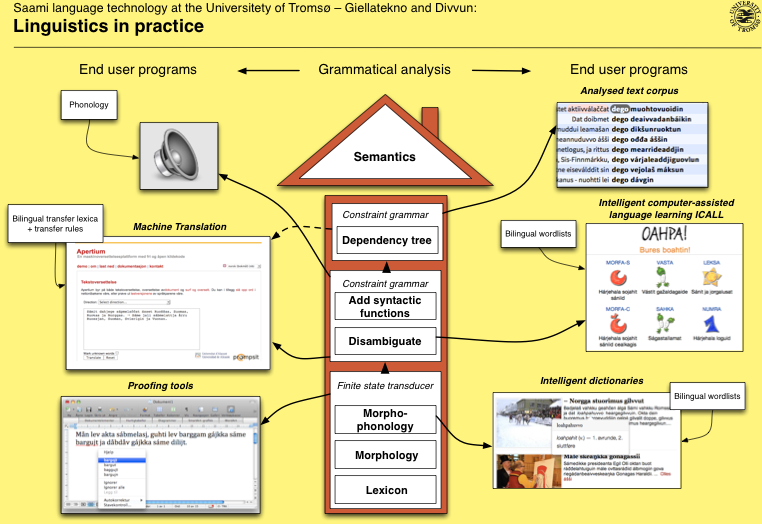
The House and the Infra
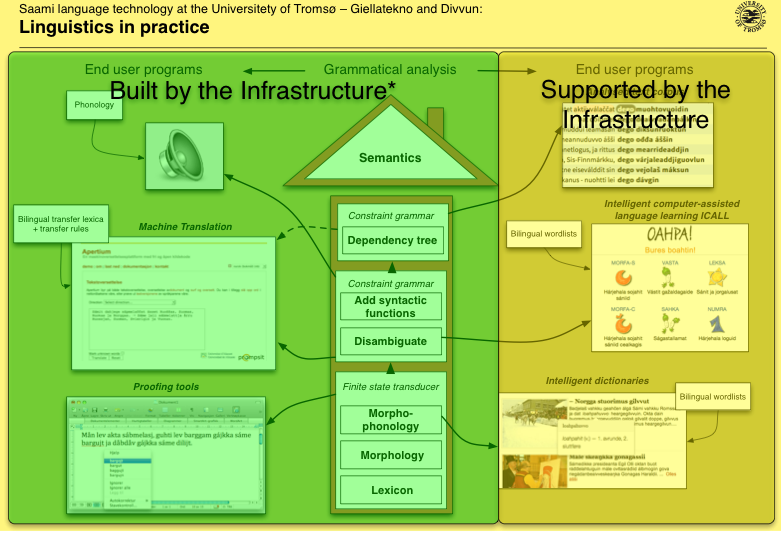
-
*Machine translation: fst's built by the infra, the rest handled by Apertium
-
*Speech synthesis is not (yet) built by the infra, conversion to IPA is part of the infrastructure though
- Supported: fst's and syntactic parsers used are built by the infrastructure
$GTHOME - directory structure
Some less relevant dirs removed for clarity:
$GTHOME/ # root directory, can be named whatever ├── experiment-langs # language dirs used for experimentation ├── giella-core # $GTCORE - core utilities ├── giella-shared # shared linguistic resources ├── giella-templates # templates for maintaining the infrastructure ├── keyboards # keyboard apps organised roughly as the language dirs ├── langs # The languages being actively developed, such as: │ ├─[...] # │ ├── crk # Plains Cree │ ├── est # Estonian │ ├── evn # Evenki │ ├── fao # Faroese │ ├── fin # Finnish │ ├── fkv # Kven │ ├── hdn # Northern Haida │ └─[...] # ├── ped # Oahpa etc. ├── prooftools # Libraries and installers for spellers and the like ├── startup-langs # Directory for languages in their start-up phase ├── techdoc # technical documentation ├── words # dictionary sources └── xtdoc # external (user) documentation & web pages
Organisation - Dir Structure
.
├── src = source files
│ ├── filters = adjust fst's for special purposes
│ ├── hyphenation = nikîpakwâtik > ni-kî-pa-kwâ-tik
│ ├── morphology =
│ │ ├── affixes = prefixes, suffixes
│ │ └── stems = lexical entries
│ ├── orthography = latin -> syllabics, spellrelax
│ ├── phonetics = conversion to IPA
│ ├── phonology = morphophonological rules
│ ├── syntax = disambiguation, synt. functions, dependency
│ ├── tagsets = get your tags as you want them
│ └── transcriptions = convert number expressions to text or v.v.
├── test =
│ ├── data = test data
│ └── src = tests for the fst's in the src/ dir
└── tools =
├── grammarcheckers = prototype work, only SME for now
├── mt = machine translation
│ └── apertium = ... for certain MT platforms
├── preprocess = split text in sentences and words
└── spellcheckers = spell checkers are built here
Technologies
- All technologies are rule-based as opposed to statistical and similar
- This allows us to write grammars that are precise descriptions of the
- Goal: The documentation for your grammar - with suitable examples etc -
Technology for morphological analysis
We presently use three different technologies:
- Xerox - closed source, not properly maintained, fast, no weights
- Hfst - open source, actively maintained, used in our proofing tools
- Foma - Open source, actively maintained, fast (newly added, not available
Technology for syntactic parsing
- Cg (VISLCG3, from University of Southern Denmark)
- used for syntactic parsing
- also for grammar checking
- Basic idea: remove unwanted readings or select wanted ones based on the
- Example:
# We like finite verbs: SELECT:Vfin VFIN ;
Templated Build Structure And Source Files
- Common resources in $GTHOME/core/
- Template for new languages, including build instructions
- The template is merged (using svn merge) with each language when updated
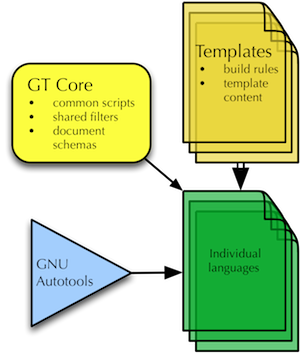
Configurable builds
We support a lot of different tools and targets, but in most cases one only
$ ./configure --with-hfst
[...]
-- Building giella-crk 20110617:
-- Fst build tools: Xerox, Hfst or Foma - at least one must be installed
-- Xerox is default on, the others off unless they are the only one present --
* build Xerox fst's: yes
* build HFST fst's: yes
* build Foma fst's: no
-- basic packages (on by default): --
* analysers enabled: yes
* generators enabled: yes
* transcriptors enabled: yes
* syntactic tools enabled: yes
* yaml tests enabled: yes
* generated documentation enabled: yes
-- proofing tools (off by default): --
* spellers enabled: no
* hfst speller fst's enabled: no
* foma speller enabled: no
* hunspell generation enabled: no
* fst hyphenator enabled: no
* grammar checker enabled: no
-- specialised fst's (off by default): --
* phonetic/IPA conversion enabled: no
* dictionary fst's enabled: no
* Oahpa transducers enabled: no
* L2 analyser: no
* downcase error analyser: no
* Apertium transducers enabled: no
* Generate abbr.txt: no
For more ./configure options, run ./configure --help
The build - schematic

Closer View Of Selected Parts:
- Documentation
- Testing
- From Source To Final Tool:
- Relation Between Lexicon, Build And Speller
Closer View: Documentation
- Background
- Implementation
Background
- Documentation is always out-of-date
- It tends to be much more out-of-date when heavily separated from the thing to
- How to improve: make it possible to write documentation within the source code
- This is similar to JavaDoc, Doxygen and many other such system
- Ultimate goal:
- Document the source code so that it can be published as the next reference
- Document the source code so that it can be published as the next reference
Implementation
- The infrastructure will automatically extract comments of a certain type, and
- One can cite portions of the source code, as well as test data.
- The syntax of the comments must follow the jspwiki syntax
Example cases:
-
https://giellalt.uit.no/lang/fin/root-morphology.html
- https://giellalt.uit.no/lang/smj/nouns-affixes.html
Documentation:
Closer View: Testing
- testing framework
- yaml tests
- in-source tests
- other tests
Testing Framework
All automated testing done within the infrastructure is based on the testing
All tests are run with a single command:
make check
Autotools gives a PASS or FAIL on each test as it finishes:

Yaml Tests
These are the most used tests, and are named after the syntax of the test files.
- a header
- test sets:
- test name
- test data
- test name
- syntax requirements: indents using spaces, multiple choices as lists within
Config:
hfst:
Gen: ../../../src/generator-gt-norm.hfst
Morph: ../../../src/analyser-gt-norm.hfst
xerox:
Gen: ../../../src/generator-gt-norm.xfst
Morph: ../../../src/analyser-gt-norm.xfst
App: lookup
Tests:
Noun - mihkw - ok : # -m inanimate noun, blood, Wolvengrey
mihko+N+IN+Sg: mihko
mihko+N+IN+Sg+Px1Sg: nimihkom
mihko+N+IN+Sg+Px2Sg: kimihkom
mihko+N+IN+Sg+Px1Pl: nimihkominân
mihko+N+IN+Sg+Px12Pl: kimihkominaw
mihko+N+IN+Sg+Px2Pl: kimihkomiwâw
mihko+N+IN+Sg+Px3Sg: omihkom
mihko+N+IN+Sg+Px3Pl: omihkomiwâw
mihko+N+IN+Sg+Px4Pl: omihkomiyiw
Yaml test output
- each yaml test file has its own line of output with PASS / FAIL /TOTAL
- at the end of each yaml test run (= all yaml files for the same fst) there
- ... followed by the Automake PASS / FAIL message
In-Source Tests
- LexC tests
- Twolc tests
LexC tests
As an alternative to the yaml tests, one can specify similar test data within
LEXICON MUORRA !!= @CODE@ Standard even stems with cg (note Q1). OBS: Nouns with invisible 3>2 cg (as bus'sa) go to this lexicon. +N: MUORRAInfl ; +N:%> MUORRACmp ; !!€gt-norm: kárta # Even-syllable test !!€ kártta: kártta+N+Sg+Nom !!€ kártajn: kártta+N+Sg+Com
Such tests are very useful to serve as checks for whether an inflectional
The syntax is slightly different from the yaml files:
- word form first
- multiple alternative word forms on separate lines
Twolc tests
The twolc tests look like the following:
!!€ iemed9# !!€ iemet# !!€ gål'leX7tj# !!€ gål0lå0sj#
The point is to ensure that the rules behave as they should.
Other Tests
You can write any test you want, using your favourite programming language.
Closer View: From Source To Final Tool:
- Relation Between Lexicon, Build And Speller
- Fst's And Dictionaries
Relation Between Lexicon, Build And Speller
- tag conventions
- automatically generated filters
- spellers and different writing system / alternative orthographies
Tag Conventions
We use certain tag conventions in the infrastructure:
-
+Err/... ( +Err/Orth, +Err/Cmp)
-
+Sem/...
- and more...
Automatically Generated Filters
- Many of these clusters of tags are used for specific purposes, and are removed
- tag using a common prefix (like +Err/ or +Sem/ gets filters for
- there are filers for:
- removing the tags themselves
- remvoing strings / words containing the tags
- removing the tags themselves
- by adhering to these conventions, you get a lot of functionality for free
- this system is used when...
Dealing with descriptive vs normative grammars
- the normative is a subset of the descriptive
- tag the non-normative forms using +Err/... tags
- write your grammar as descriptive
- remove the +Err/... strings
- => normative fst!
Summary
- scalability
- division of labour
- language independence
- ... but still flexible wrt the needs of each language
Giitu
- Thank you!