
New InfraBAULT Presentation
The Giellatekno & Divvun infrastructure
Presentation at the BAULT seminar, HU 5.6.2014
Sjur Nørstebø Moshagen, Divvun, UiT Norgga árktalaš universitehta
Content
- overview
- the core
- templates and merging
- languages
- linguistic data
- build structure
- testing
- documentation
- the tools we produce
- concluding remarks
Overview
Main points for the design of the infrastructure:
- scalable and extendable:
- support many languages and the creation of many tools for each language
- support many languages and the creation of many tools for each language
- open source
- (relatively) easy to maintain (as few repetetive tasks as possible)
- support existing source code and language technology -> lexc/twolc/xfst scripts + vislcg3 (all with open-source compilers and run-time engines)
Developed by Tommi Pirinen and Sjur Moshagen.
A schematic overview of the main components of the infrastructure:
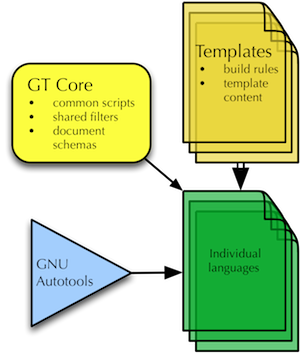
The Core
- templates for data and build files
- shared data
- shared scripts/programs
- document schemas
Available at:
svn co https://gtsvn.uit.no/langtech/trunk/giella-core
Templates For Data And Build Files
The template contains template data for the actual linguistic content. The idea is that when initialising a new language, you should get a working setup, with a working set of tools (analysers, generators, spell checkers, etc) for a toy language, and from there on you add your own, real content. The reality isn't quite there, but not too far away either.
The template also contains configuration and build instructions, both language independent parts, and support for language specific build steps. The language independent parts are kept in a separate directory, to avoid accidental changes and easy reuse of general build instructions.
Shared Data
The shared data comes in two flavours:
- shared linguistic data
- common or language independent regular expressions for fst manipulation
Shared linguistic data typically is shared only for a subgroup of languages, like smi and urj-Cyrl.
The regular expressions are made to remove tags or tagged strings of classes typically found in all languages:
- remove non-standard strings (to make a purely normative fst)
- remove semantic tags from fst's where they are not used
- remove morphological boundary symbols from the lower/surface side
- etc.
There are presently 52 such regexes.
Other shared items
- Shared Scripts/Programs
- Document Schemas
Templates And Merging
- template content
- merging the template
Template Content
Briefly described earlier, this is what you will find:
- lexc files
- twolc/xfscript files
- cg3 files
- in short, everything you need for your source files
... or in a picture:
Template content layout
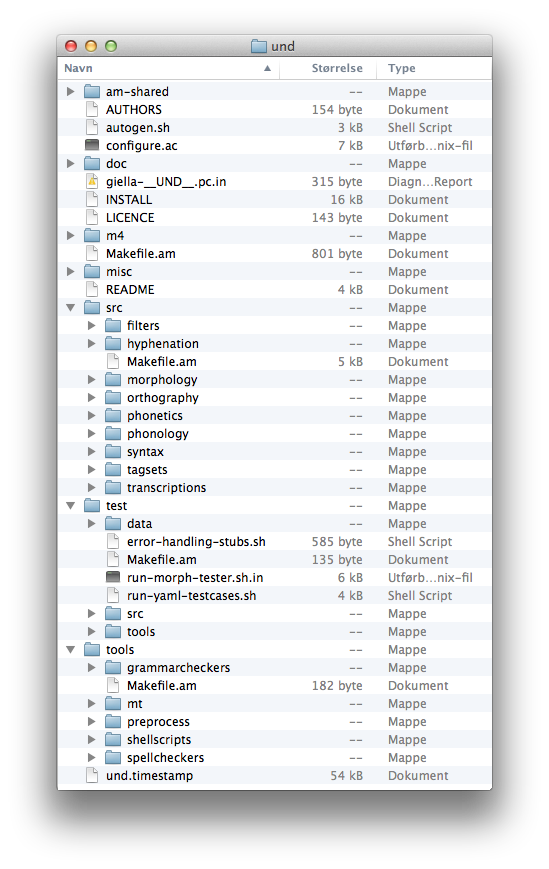
Template content layout as ASCII art
.
├── am-shared
├── doc
├── src
│ ├── filters
│ ├── hyphenation
│ ├── morphology
│ │ ├── affixes
│ │ └── stems
│ ├── orthography
│ ├── phonetics
│ ├── phonology
│ ├── syntax
│ ├── tagsets
│ └── transcriptions
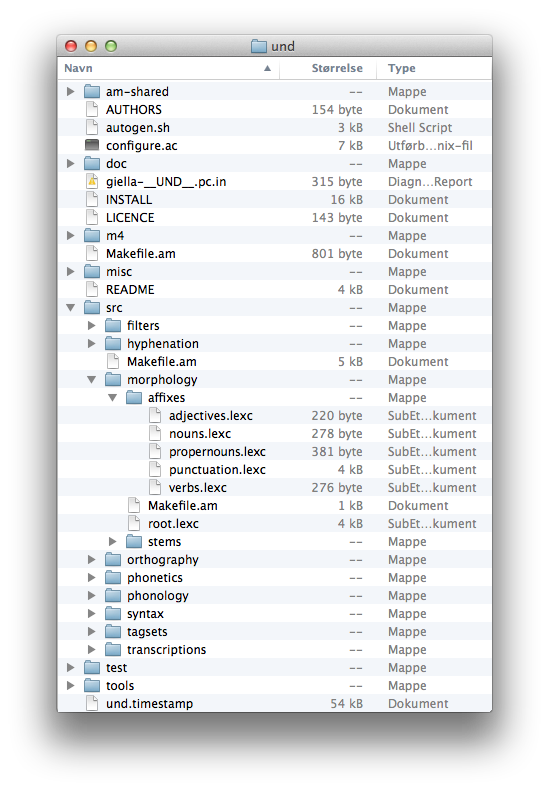
├── test
│ ├── data
│ ├── src
│ │ ├── dict-gt-yamls
│ │ ├── gt-desc-yamls
│ │ ├── gt-norm-yamls
│ │ ├── morphology
│ │ ├── phonology
│ │ └── syntax
│ └── tools
│ ├── mt
│ │ └── apertium
│ └── spellcheckers
└── tools
├── grammarcheckers
├── mt
│ └── apertium
│ ├── filters
│ └── tagsets
├── preprocess
├── shellscripts
└── spellcheckers
├── fstbased
│ ├── foma
│ └── hfst
└── listbased
└── hunspell
Template Content (II)
This also shows the use of the Autotools basic structure, with such items as:
- m4 dir
- configure.ac
- AUTHORS, LICENSE and README etc.
- Makefile.am files
Merging The Template
One of the main features of the infra is the relative ease with which one can update all or any language with new features or bug fixes in the build instructions. This is done by merging recent changes in the template with the corresponding files in each language.
- by default, only non-content files and new files are merged (new files are copied), but that can be overridden
- the merge is done from the revision of the und.timestamp file in each language compared to that of the same file in the template, no older files are ever merged
- svn merge is the tool used to do the merges
- by separating the language specific files from the language independent parts merge conflicts rarely happens
- depending on network conditions (the incoming merge data is fetched from the svn repository) and the number of files to be merged, merging 40+ languages can be done in a couple of minutes (+ some time to manually verify that everything worked as intended)
- This merge system is also used to propagate new features and support for new tools. E.g. adding build support for a foma-based speller used by Greenlandic took a couple of hours to figure out the details for one language, and when done, it took just minutes to propagate to all languages.
Languages
We have split the languages in four groups, depending on the type of work done on them, and their license:
- langs
- These are the languages being actively developed - 43 languages
- startup-langs
- These are languages that someone has an interest in, but are not actually being developed, and where the linguistic content is thin - 11 languages
- experiment-langs
- The name says it all - this is the playground, and they are a.o. used for teaching - 3 languages
- closed-langs
- These are languages with a closed license, only ISL and DAN at the moment
Available at:
svn co https://gtsvn.uit.no/langtech/trunk/langs/ISO639-3-CODE/
(replace ISO639-3-CODE with the actual ISO code)
And more languages
We still have a number of languages located in an older infrastructure system - these will be moved to the new infra as time permits.
Linguistic data
Formats:
- lexc
- twolc
- xfst scripts
- constraint grammar (VISLCG3 style)
Standardised tag sets:
- non-linguistic tag sets the same for all languages
- linguistic tags the same or similar as far as possible
- "namespace"-like prefix for certain domains, e.g. +Err/ and +Sem/
Build Structure
Support for:
- in-source documentation (converted to html)
- in-source test data
- automated tests
- all tools built for all languages - but not everything built by default
- basically technology neutral, but focused on rule based systems (fst's, cg)
- all languages structured the same way
- separation of language independent and language specific features
- all builds are language independent, but most (eventually all) build steps allow a language specific post-build step
Build tools
- we use Autotools, which is widely used in the open-source community
- built-in support for a number of default/standard targets
- built-in support for automated testing
- easily configurable builds with options in a standardised format
- support for out-of-source builds and multiple parallel configurations
Language Specific Adaptions In The Build Process
This is done by first building a *.tmp file, and using a fall-back target that just copies the *.tmp file to the final target. By overriding the copy step, one can do whatever one needs to do for a specific target after the default, language-independent processing is done.
The language-specific build steps are specified in a (mostly) clearly marked section in the Makefile.am files.
Testing
Testing is done with the command make check, as in all Autotool-based build
- in-source test data in lexc and twolc
- specific test files for testing morphological analysis and generation against
In addition, there is the general support for testing in Autotools (or more specifically in automake), meaning that it is possible to add test scripts for whatever you like.
Test directory
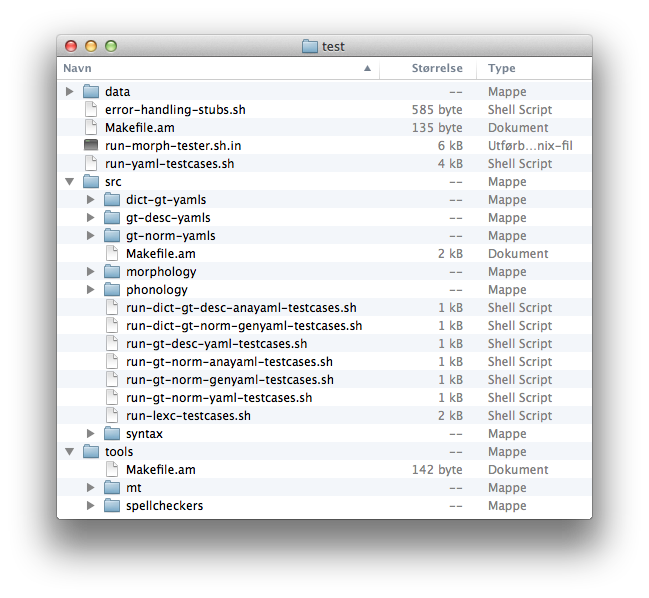
Yaml tests
- test files written using yaml syntax
- the test data follows a very simple layout (in addition to a header):
Adjective - gielak: # AGAdj
gielak+A+Attr: gielak
gielak+A+Sg+Nom: gielak
gielak+A+Sg+Acc: gielagav
gielak+A+Comp+Sg+Nom: []
gielak+A+Superl+Sg+Nom: []
Tests both generation (absolute match) and analysis (ignoring homonymy) for the specified fst (specified in the filename of the yaml file). The test runner will loop over all matching yaml files, run all tests in each file, and if one file fails, it will print out a command to copy & paste to repeat the test with all details visible.
Example (line wraps added for readability):
YAML test 37: analyser-gt-norm.xfst + gt-norm-yamls/N-aambaz_gt-norm.yaml - 30/0/30 PASS YAML test 38: analyser-gt-norm.xfst + gt-norm-yamls/N-aandam_gt-norm.yaml - 26/2/28 FAIL To rerun with more details, please triple-click, copy and paste the following: pushd $GTHOME/langs/liv/build/xerox/test/src; \ /opt/local/bin/python3.2 \ $GTHOME/giella-core/scripts/morph-test.py -c -i -v -S xerox \ --app /Users/smo036/bin/lookup \ --morph ././../../src/analyser-gt-norm.xfst \ --gen ././../../src/generator-gt-norm.xfst \ ../../../../test/src/gt-norm-yamls/N-aandam_gt-norm.yaml; popd
Lexc tests
The in-source lexc tests are actually a variant of the yaml tests,
!!€gt-norm: linja # Even-syllable test !!€ linnja linnja+N+Sg+Nom !!€ linjajn linnja+N+Sg+Com !!€ linjav linnja+N+Sg+Acc
The first line specifies the fst to run the test against and the name of the
All lexc files are looped over, and if test cases are found, they are extracted
Twolc tests
If one wants to test specific two-level rules one can add test pairs to the
The test data looks like the following:
!!€ roavggoX4j !!€ roavggu0j !!$ roavggoX4j !!$ r0åvggu0j
The yaml and lexc tests will also de facto test the correctness of the two-level
Documentation
The infrastructure supports extraction of in-source documentation written as
The basic idea is that documentation that is part of the actual source code is
The format supports the use of a couple of variables to extract such things as
Documentation example
! ====================== !! !!!Sublexica for Noun ! ====================== !! !!Even-syllable stems ! ------------------- !! !2syll stems ! - - - - - - LEXICON MUORRA !!= @CODE@ Standard even stems here. 2syll stem with cg (note Q1)
This will produce the jspwiki code:
!!!Sublexica for Noun !!Even-syllable stems !2syll stems LEXICON MUORRA Standard even stems here. 2syll stem with cg (note Q1)
which can be seen rendered online as html here:
The Targets, Tools And Packages Produced By The Infrastructure
The list is constantly growing and contains roughly the following at present:
- morphological analysers for different purposes
- morphological generators for different purposes
- syllabification transducers
- orthographic-to-phonetic transcripting transducers
- number-to-text and vv transducers
- tagset converters
- disambiguators
- syntactic parsers
- dependency parsers
- spell checkers:
- hfst+voikko
- foma
- hfst+voikko
- a package of adapted analysers, generators and cg3 files for Apertium MT
- a simple command-line tool to use installed fst's from anywhere on the system
Coming and future tools and packages
Projects being worked on right now that will lead to new tools for all languages
- hunspell converter
- hyphenators of various kinds (already supported in the old infrastructure)
- grammar checker
On a slightly longer scale there are plans for:
- proper packaging and distribution of the giella-core and each language
- support for speech based applications (speech synthesis)
Concluding remarks
- The Giellatekno & Divvun infrastructure provides a rich development
- quite a few languages are already using this infrastructure, mainly
- it is all open source
- it is scalable and extendable
- it provides a short distance from development to tools for the language community
More info at https://giellalt.uit.no/infra/GettingStarted.html
Thank you! Kiitos!
Thanks for your attention!