
Edmonton Infrastructure Presentation
Presentation of the Divvun and Giellatekno infrastructure
University of Alberta, Edmonton, June 19th
Sjur Moshagen & Trond Trosterud, UiT The Arctic University of Norway
Content
- Background
- Introduction
- The core
- The languages
- Build structure
- Testing
- Documentation
- The tools we produce
- Summary
Background
The problem
- Our original ("old") infrastructure
- was based upon copy and paste from language to language
- treated different languages differently, for historical reasons
- was based upon copy and paste from language to language
- new languages was added all the time
- also new features and new tools were added for some languages,
- ... but they would not become available for other languages without
- ... but they would not become available for other languages without
- Hfst was added as a hack on top of the support for the Xerox tools
- (Xerox = the first fst compiler; Hfst = an open-source implementation)
- (Xerox = the first fst compiler; Hfst = an open-source implementation)
- it was way too time-consuming and boring to maintain (mainly by Sjur)
The plan
To create an infrastructure that:
- scales well both regarding languages and tools
- has full parity between Hfst and Xerox
- treats all languages the same
- is consistent from language to language, supporting cross-language cooperation
- ... while still being flexible enough to handle variation between the
The solution

Details in the rest of the presentation.
Introduction
Developed by Tommi Pirinen and Sjur Moshagen.
A schematic overview of the main components of the infrastructure:
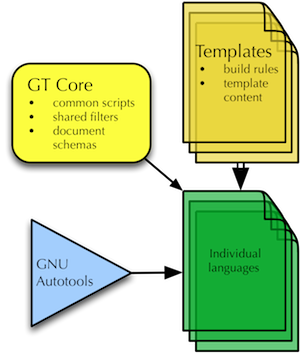
General principles
- Be explicit (use non-cryptic catalogue and file names)
- Be clear (files should be found in non-surprising locations)
- Keep conventions identical from language to language whenever possible
- Divide language-dependent and language-independent code
- Modularise the source code and the builds
- Reuse resources
- Know the basic setup of one language -- know the setup of them all
- Possibility for all tools to be built for all languages
- Parametrise the build process
What is the infrastructure?
- a systematic way to go from source code to compiled modules
- a framework for testing the modules
- a way of chaining the modules together into larger functional units
For this to work for many languages in parallel and at the same time, we need:
- conventions
- a fixed directory structure
- a shared build system
Conventions
We need conventions for:
- filenames
- tags
- file locations
E.g., your source files are located in src/:
- in the folders morphology/stems, morphology/affixes, phonology, ...
- stem files: nouns.lexc, verbs.lexc, particles.lexc, ...
- affix files: nouns.lexc, verbs.lexc
Directory structure
In detail:
.
├── am-shared
├── doc
├── misc
├── src
│ ├── filters
│ ├── hyphenation
│ ├── morphology
│ │ ├── affixes
│ │ └── stems
│ ├── orthography
│ ├── phonetics
│ ├── phonology
│ ├── syntax
│ ├── tagsets
│ └── transcriptions
├── test
│ ├── data
│ ├── src
│ └── tools
└── tools
├── grammarcheckers
├── mt
│ └── apertium
├── preprocess
├── shellscripts
└── spellcheckers
Explaining the directory structure
.
├── src = source files
│ ├── filters = adjust fst's for special purposes
│ ├── hyphenation = nikîpakwâtik > ni-kî-pa-kwâ-tik
│ ├── morphology =
│ │ ├── affixes = prefixes, suffixes
│ │ └── stems =
│ ├── orthography = latin <-> syllabics, spellrelax
│ ├── phonetics = conversion to IPA
│ ├── phonology = morphophonological rules
│ ├── syntax = disambiguation, synt. functions, dependency
│ ├── tagsets = get your tags as you want them
│ └── transcriptions = convert number expressions to text or v.v.
├── test =
│ ├── data = test data
│ ├── src = tests for the fst's in the src/ dir
└── tools =
├── grammarcheckers =
├── mt = machine translation
│ └── apertium = ... for certain MT platforms
├── preprocess = split text in sentences and words
├── shellscripts = shell scripts to use the modules we create
└── spellcheckers = spell checkers are built here
The core
The core is a separate folder outside the language-specific ones.
- templates for the languages
- scripts used for maintenance and testing
- shared resources
- linguistic resources shared among several languages
- language independent fst manipulation
- linguistic resources shared among several languages
Shared resources
The shared resources come in two flavours:
- shared linguistic data
- language independent fst manipulation
Shared linguistic data typically is shared only for a subgroup of languages,
The fst manipulations remove tags or tagged strings of classes typically found
- remove non-standard strings (to make a purely normative fst)
- remove semantic tags from fst's where they are not used
- remove morphological boundary symbols from the lower/surface side
- etc.
Languages
We have split the languages in four groups, depending on the type of work done
- langs
- These are the languages being actively developed - 43
- startup-langs
- These are languages that someone has an interest in, but
- experiment-langs
- The name says it all - this is the playground, and these
- closed-langs
- These are languages with a closed license, only ISL and
Available at:
svn co https://gtsvn.uit.no/langtech/trunk/langs/ISO639-3-CODE/
(replace ISO639-3-CODE with the actual ISO code)
Build Structure
Support for:
- in-source documentation (converted to html)
- in-source test data
- automated tests
- all tools built for all languages - but not everything built by default
- basically technology neutral, but focused on rule based systems (fst's, cg)
- all languages structured the same way
- separation of language independent and language specific features
- all builds are language independent, but most (eventually all) build steps
Testing
Testing is done with the command make check. There is built-in support for
- in-source test data in lexc and twolc
- specific test files for testing morphological analysis and generation against
In addition, there is the general support for testing in Autotools (or more
Documentation
The infrastructure supports extraction of in-source documentation written as
Documentation written in the actual source code is
The format supports the use of a couple of variables to extract such things as
The tools
- Analysers
- Generators
- Number transcriptors
- Specialised analysers and generators
- Spellrelax
- Disambiguators and parsers
- Spellers
- Grammar checkers
The pipeline for analysis
- take text
- preprocess it (sentences, words)
- give all morphological analyses
- pick the correct ones
- add grammatical functions
- add dependency relations
The pipeline for grammar checking
- take text
- preprocess it (sentences, words)
- give all morphological analyses
- make a sloppy disambiguation ("do not trust the input")
- find error patterns
- mark them
- give message to the writer
Two startup scenarios
- Add a new language that does not have machine-readable resources ("Blackfoot")
- Add an existing morphological analyser in an incompatible format,
In the latter case it could be possible and even preferable to script the
Summary
- This infrastructure makes it possible to
- work with several languages
- get several tools and programs out of one and the same source code
- work with several languages
- It is continuously under development
- ... all new features automatically become available to all languages
- ... all new features automatically become available to all languages
- It is documented
- ... and it is available as open source code