
Designing Resources
This document explores some of the issues that come up when preparing
Intro
As an experiment, I took a look at creating an NDS instance with Irish, which
Data was first converted to TSV, under the belief that it would be easier to
Initial thoughts
- Who are your users? How skilled might they be with the languages? Advanced
Priorities?
If your first concern is where it's best to spend more time, it seems like that
The reason more time should be spent on the lexicon, is because you'll see
With Irish, since my primary source was a wordnet, there were a lot of
ól (n) -
drink
drinking
boozing
drunkenness
crapulence *
drinking
imbibing
imbibition
liquor
spirits
booze
hard drink
hard liquor
John Barleycorn *
strong drink
With a wordnet, I probably have automated ways of resolving this-- but with a
Lexicon
Discovered issues:
- A newly parsed lexicon had too much. Became important to trim it down:
- restrict translations by matching POS of both sides
- consider lemmatizing both sides, and discarding non-lemmas or giving them
- be careful with the amount of annotations <re /> and <te />
Morphology / FST
The dictionary may serve as a quick way to test your morphology for both
Discovered issues
- Words do not generate
- Generation is surprisingly slow (9 forms for a paradigm may add up if
- Words generate incorrectly
- Words are not analyzed
Refinements
For pedagogical lexica, you may want to produce pre-generated paradigms for
Sentence examples
<tg xml:lang="nob">
<t pos="Pron" type="Pers">sørligst</t>
<xg>
<x>Lulimus báiki Norggas lea Lindesnes.</x>
<xt>Den sørligste plassen i Norge er Lindesnes.</xt>
</xg>
</tg>

Index entries
Sometimes there isn't an easy way of representing a translation of a word
1.) Step one:
hverandre -> choose person (two people, more than two people)
2.) Step two:
hverandre (about two people) -> choose case
- from eachother (locative)
- to eachother (illative)
- with eachother (commitative)
3.) Step three: present definitions.
TODO: images
This requires some specific formatting in the XML:
- <l til_ref="hverandre" />
- <re fra_ref="omtopersoner">
- <l orig_entry="hverandre">
<e>
<lg>
<l pos="Pron" type="Recipr" til_ref="hverandre">hverandre</l>
</lg>
<mg>
<tg xml:lang="sme">
<re fra_ref="omtopersoner">om to personer</re>
<t/>
</tg>
</mg>
<mg>
<tg xml:lang="sme">
<re fra_ref="omflerepersoner">om flere enn to personer</re>
<t/>
</tg>
</mg>
</e>
<e>
<lg>
<l pos="Pron"
type="Recipr"
orig_entry="hverandre"
til_ref="omtopersoner">hverandre: om to personer</l>
</lg>
<mg>
<tg xml:lang="sme">
<re fra_ref="2hverandrelok">fra hverandre (lokativ)</re>
<t/>
</tg>
</mg>
<mg>
<tg xml:lang="sme">
<re fra_ref="2hverandreill">til hverandre (illativ)</re>
<t/>
</tg>
</mg>
<mg>
<tg xml:lang="sme">
<re fra_ref="2hverandreess">som hverandre (essiv)</re>
<t/>
</tg>
</mg>
<mg>
<tg xml:lang="sme">
<re fra_ref="2hverandreakkgen">hverandre (akkusativ-genitiv)</re>
<t/>
</tg>
</mg>
<mg>
<tg xml:lang="sme">
<re fra_ref="2hverandrekom">med hverandre (komitativ eller adverb)</re>
<t/>
</tg>
</mg>
</e>
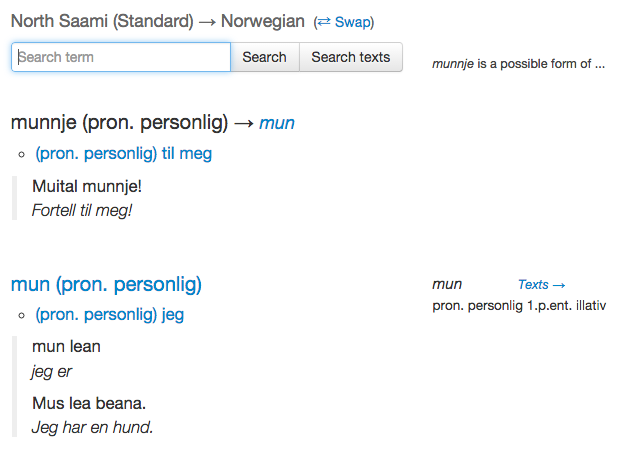
<e>
<lg>
<l pos="Pron" type="Pers">munnje</l>
<lemma_ref lemmaID="mun_pron_pers">mun</lemma_ref>
<analysis>Pron_Pers_Sg1_Ill</analysis>
</lg>
<mg>
<tg xml:lang="nob">
<t pos="Pron" type="Pers">til meg</t>
<xg>
<x>Muital munnje!</x>
<xt>Fortell til meg!</xt>
</xg>
</tg>
</mg>
</e>
-->
<e>
<lg>
<l pos="Pron" type="Pers">mun</l>
<analysis>Pron_Pers_Sg1_Nom</analysis>
</lg>
<mg>
<tg xml:lang="nob">
<t pos="Pron" type="Pers">jeg</t>
<xg>
<x>mun lean</x>
<xt>jeg er</xt>
</xg>
<xg>
<x>Mus lea beana.</x>
<xt>Jeg har en hund.</xt>
</xg>
</tg>
</mg>
</e>
Troubleshooting
- Sometimes no entries would display, mostly this was due to XML formatting
- The analyzer was out of line with the lexicon for i.e., POS, some tweaks
Morphology
Discovered issues
- 500 error with the output
500 Whoops! There was some kind of error. Invalid tagset <pos>. Choose one of:
- create and add the language-corresponding tagset-file
neahtta/configs/language_specific_rules/tagsets
Troubleshooting
Reader
- Determine special characters in the language that will break up the user's
an t-éas
Niceties
1. Morphological tags should be relabeled into a user friendly means. See: TODO
TODO: images
3. Additional annotations can be added to the lexicon and displayed to the