
Implementation plan for corpus interfaces
Introduction
Implementation plan for corpus interfaces
The document is partly based on the discussion with the people in Textlaboratoriet (the memo), and discussions in Saletek seminar, July 2004.
Overview and introduction
The main goal of the corpus subproject is to build an extensive and versatile source of text materials for Saami languages. The main goals of the project is to collect and develop the corpora in co-operation with the owners of the texts and to provide easy access to the text materials for non-commercial purposes such as research. The text materials will be available through a query processing tool: a tool with which a user can fetch different types of data from the Sámi corpora.
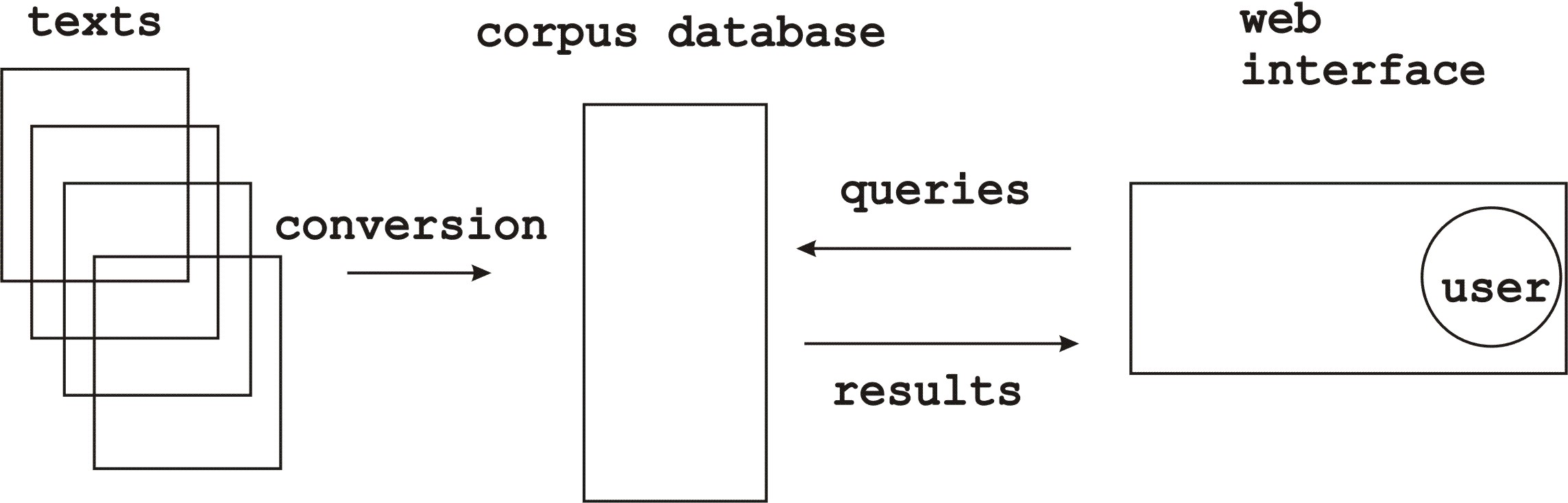
The available texts will be moved to a corpus database which is accessed by the users through a web-interface, cf. .
The overall architecture of the system
{kind=link}
Where the material is available in different languages such as New Testament, a parallel corpora is created.
This document describes the plans for implementing the corpus database and the query system.
All the material concerning the corpus project is currently stored in the directory gt/cwb/ under cvs.
The corpus database
The morphologically analyzed texts are stored in XML-format, which forms the corpus database. The XML-format is used as the base format for creating different views to the corpora. The queries are made available by a corpus processor tool. The project has licensed corpus software tools from IMS Stuttgart (the CQP of the IMS Stuttgart Corpus bench). The IMS Cropus Workbench is a tool for performing searches to large text corpora.
The CWB-toolbox is installed to victorio, the usage of the tools is briefly introduced in section IMS Corpus Workbench: demo
The XML-format of the corpus texts is documented in section XML-format of the corpus files.
In addition to actual texts, the corpus database contains other textual information such as author, date, genre and region that can be exploited for example in studies considering for example regional or historical variety. The other textual information is stored in separate header files, documented in section Meta information.
The work flow of converting the available text material to the corpus database includes the following steps:
- Cleaning of the original text
- Preprocessing
- Morphological tagging
- Manual check
- Conversion to XML-format
- Adding meta information
- Conversion to IMS-format
The texts often arrive in some other than a plain text format, such as pdf or MS Word. There are some tools for cleaning both types of texts, as well as html. The tools and usage are described in section Cleaning up the original text. This step also involves the character conversion to the project internal 7-bit encoding (the special characters are presented as digraphs: c1, s1, etc.).
The next step is to cut the text in the sentences and word tokens. The preprocessor is documented in preprocessor.html. The preprocessor tool may have to be adapted to the corpus project, if the text contains for example some xml-formatting. The modifications are not yet implemented nor planned.
Step three is implemented by analysis and disambiguation tools.
As long as there are problems with either preprocessing or analysis and disambiguation the step three, manual check, is hard work. When the other tools are reliable only spot checks are needed.
The meta information is described in section Meta information.
The conversion to XML-format is described in XML-format of the corpus files
The conversion to IMS-format is not yet implemented, nor fully planned. In this part, we rely to the help of Textlaboratoriet in the University of Oslo.
Cleaning up the original text
The cleaning of the corpus documents involves removing all the formatting which is not relevant for the corpus database or morphpological analysis. The original shape of the document should be preserved: the headings and lists as separate paragraphs etc. Perhaps later we want to move some formatting to XML as well.
There are couple of tools installed for cleaning the texts: antiword and wvWare. Antiword does simple word to text and html converting, wvWare involves more formats and conversion options.
The documentation of antiword is antiword.man and the usage for example converting an utf-8 coded MS Word document to the 7bit project-internal format:
$ antiword -m UTF-8.txt file.doc | utf8-7bit.pl > file.txt
The information of wvWare can be found from packages' man page:
$ man wvWare
XML-format of the corpus files
The XML format of the analyzed text is basically the following:
<text> <sentence> <token form="The" lemma="the" POS="DET" /> <token form="flies" lemma="fly" POS="N" /> </sentence> </text>
Optionally, one can
- enclose several texts in a corpus-tag
- use a paragraph-tag enclosing several sentence-s
- use more attibutes:
- on all elements: type and language
- on tokens: morphology, syntax etc.
- have several readings for each token:
<token form="flies"> <reading lemma="fly" POS="N" /> <reading lemma="fly" POS="V" /> </token>
There is a first version of the dtd corpus.dtd for the format. In addition, there is a file sme_tagset.ent which contains the names of the tag classes. This is supposed to make the dtd more flexible, since the tag classes may change among languages.
The conversion from CG2-output to XML is handled by a script convert2xml, the script requires the tag file korpustags.txt to get the tagsets right.
In the applications, the Perl modules such as XMLTwig are used for parsing XML. Emacs is a fairly good tool for editing XML, but it might be a good idea to install a separate xml-processor as well. Apache's Xerces seems to be a good and widely used tool for xml parsing and generation.
Meta information
The structural information is encoded in XML-format, following for example the CES standard. Then there would be three different categories of information for each corpus: Global information of the text and its content: author, character set, etc. corresponding TEI header. Primary data, which includes structural units of text etc. abbreviations and so on. And linguistic annotation, including morphological and syntactic information, alignment etc. The queries to the documents would then be made by tools designed for processing XML.
However, the query system offered by IMS Corpus Workbench does not support SGML in full extent. Rather, the structural information offered by IMS-tools is rather restricted. The query engine CQP uses regular expressions in corpus queries, which is a desired feature. The structural information cannot be queried at all by CQP, it is only available in the results.
The global information can be transferred to CQP searchable format, for example by transferring the header information to attributes in IMS. The header information may also be consisted as a string in one attribute.
The exact format of the corpus header files is not yet planned.
Transforming the corpus files to IMS-format
The "Corpus administrator's Manual" describes in detail, how the text corpus is transformed to the internal representation used by the IMS toolbox. As we have desided to use XML for the basic format of the corpora, suitable conversion tools from XML to the format required by IMS have to be developed.
There will be conversion scripts from XML-format to TEI and IMS corpus workbench, provided by Textlaboratory.
The web-interface
The web-interface will be provided by Textlaboratory.
Files and directories
The corpus files themselves will be placed to /usr/local/share/corp/ for now. The subdirectory doc contains the original texts in their original formatting. Later, there should be separate directory for all the corpus files.
The location of the corpora has to be planned with Roy, the files can be quite big and need not to be backuped daily (but weekly or monthly will be ok). Perhaps some globally accessible, separate filesystem, for example directory /corpora.
At the moment the corpus files are stored to cvs. The corpus files are modified all the time for testing purposes, so cvs is ok. Also the size of the corpus is fairly small, about 34M altogether. Tagged corpus is obviously much bigger but at the development phase it will not cause any problems.
However, the usage of cvs for storing large corpora is impossible if the files gets much bigger. This is because every user has his own copy of all the files and also the modifications between versions that are stored to repository may grow. The size of ims-format corpus can be some 10-50 times bigger than the original raw text, depending on the amount of tags (the number is just a hasty estimate).
The CWB installation and directories
The version of the software is 3.0 and the installed archive name was cwb-2.2.b72-i386-linux.tar.gz. The up-to-date information was available at ftp://ftp.ims.uni-stuttgart.de/pub/outgoing/cwb-beta/index.html.
The software is installed to directory /usr/local/cwb. The environment variable PATH has to be updated:
export PATH=$PATH:/usr/local/cwb/bin
There are specific corpus registry files which contain information on the corpus, like where the data is stored. The registry files should be in one place, perhaps in the same place as the corporal, in directory /corpora/registry. The environment variable CORPUS_REGISTRY has to be set.
Information in the corpus
Morphological information in the corpus
The corpus contains tokens (words) and other positional attributes such as part-of-speech tags. The tags are arranged one in each column. The columns are separated by tab.
Corpus tags
There are the following tag categories:
- Part of speech: N A V Adv Pron CS CC Adp Po Pr Interj Pcle Num
- Number or Person/Number: Sg Pl Sg1 Sg2 Sg3 Du1 Du2 Du3 Pl1 Pl2 Pl3 ConNeg
- Case: Ess Nom Gen Acc Ill Loc Com
- Possessive suffix: PxSg1 PxSg2 PxSg3 PxDu1 PxDu2 PxDu3 PxPl1 PxPl2 PxPl3
- Clitic: Qst Foc
- Grade: Comp Superl
- Attribute: Attr
- Derivation (We must consider whether to use these..): Pass h upmi ...
- Polarity: Neg
- Mood: Ind Pot Cond Imprt ImprtII
- Tense: Prs Prt
- Nominal verb form: Inf Act PrsPrc PrfPrc VGen VAbess Ger ConNeg ConNegII
- Pronoun type: Pers Dem Interr Refl Recipr Rel Indef
- Other: PUNCT CLB ABBR ACR
- Punctuation type: LEFT RIGHT
- Num type: Ord Card
Structural information
It is possible to mark for example the beginning and end of a sentence to the corpus file by using SGML-like markers. Whether we should use that or not is dependent upon what benefits it may give us, seen from the ims framework point of view. Changing the tag CLB etc. to SGML-like markers is not a problem, but it is unclear to what extent it helps either parsing or corpus processing.
Large units of discourse information are:
- headings
- lists
- chapters
- paragraphs?
- footnotes etc.
Smaller units:
- sentences
- abbreviations
- dates
- quotations
- names
We have to find out what kind of information it is possible to extract from diffeent types of documents, and how much of the structural information can be extracted automatically.
In Microsoft Word format, the information is in the underlying representation. A priori, it should be possible to write an MSW macro to turn this into textual informaion prior to the "save as enriched text" command that we use to convert MSW documents to our internal format. Seen from a disambiguation point of view, information on paragraphs and bulletpoint lists is clearly a valuable resource, if we can write rules that rely on such information (demand finite verbs form sentences, not from titles, parenthesis fragments or bulletpoint items).
IMS Corpus Workbench demo
IMS Corpus Workbench is now installed to victorio and can be tested with two demo corpuses. There is English demo corpus which consists of Charles Dickens novels and German demo corpus of law texts. The corpora is accessed using the corpus query processor CQP. To get CQP working, add these lines to your .bashrc:
export PATH=$PATH:/usr/local/cwb/bin
export CORPUS_REGISTRY=/usr/local/cwb/registry
Start CQP by typing
cqp
To the shell prompt. Leave the program by typing exit; or Ctrl-D. I recommend to turn off the highlighting by
set Highlighting no;
The command show; shows the installed corpora. To select the Dickens corpus, type
DICKENS;
To make a query, follow the instructions in the CQP Tutorial (path: /usr/local/cwb/doc/CQP-Tutorial.2up.pdf).
Saami demo corpus
There is one short Saami demo corpus with limited tags, stme1029. To make queries to it, type
STME1029;
to cqp prompt.
The tags used in the corpus are listed in the tag list: gt/cwb/korpustags.txt. Commented lines are marked with '%', the line that starts with hash (#), marks the tag class, e.g. POS. Under it is the list of the tags which belong to that class, in case of POS, N, Adj, V, etc.
The corpus file is first converted to a format where each word is in its own line followed by base form and the tags associated to it. Tags are separated by TAB. See file /usr/local/cwb/demo/stme1029/stme1029.vrt (in directory /usr/local/cwb/demo/stme1029 for example. The coversion from CG2 output to word-list format is done automatically by using script convert2cwb.
Some not so relevant documentation
XCES
XCES is an XML-version of CES. It allows the usage of XML-tools to corpus files. The tag names are the same as in CES. In practise, a corpus file is divided two sections, header and body text. The header is encoded using XCES, the text section with morphological and syntactic tags in IMS tabular format. We will see, how to ensure the compatibility of these two formats. Either we could have the XCES header in a separate file. INL's (Institutt for nordistikk og litteraturvitskap) corpus project SLM (Seksjon for lexikografi og m�fregransking) has solved the problem som way, so I will trust that it is possible for us too. Next I will go through INL's header specifications and see how they should be modified for the Sami corpora.
Tag specifications
INL have different kind of headers for different type of texts. We have to see if that is necessary. We have different types of corpora, books, articles, law texts, etc.
bokerSA.txt cesDoc starts the document. It contains document id id and language lang.
cesHeader starts the header. It has the following sections:
< fileDesc> < /fileDesc> < encodingDesc> < /encodingDesc> < profileDesc> < /profileDesc> < revisionDesc> < /revisionDesc>
fileDesc for the bibliographic description of the corpus.
I describe only the content elements.
- h.title contains the name of the document.
- respStmt is the information about the person or institute of the intellectual content of the text.
- wordCount is the count of words in the text,
- byteCount the number of bytes (the text together with its markup).
- extNote is for additional information
- distributor gives the name of institution who distributes the text or corpus.
- pubAddress postal address of the distributor
- eAddress the distributor's electronic address
- availability the restrictions to the use or distribution, e.g. copyright
- pubDate the publication date
- If the text is published not as an independent publication,
the following information is inside
analytic-tag. Otherwise the tag
monogr is used.
- h.title full title
- h.author name of the author
- edition edition
- publisher
- pubDate
- pubPlace
- idno ISBN or equivalent
- biblScope The scope of the bibliographic reference, e.g. page numbers
- biblNote note
The encoding description encodingDesc describes the relation between the text and its original source.
- taxonomy The classification taxonomy
- category The category in the taxonomy
The Profile description profileDesc, contains the language etc.
- language The id of the language. If more than one language is specified, it is possible to use < foreign xml:lang=nb> bokm� word </foreign> tags in the text.
- writingSystem specifies the writing system, there can be more than one specified as well.
- textClass text classification scheme and keywords.
- catRef defines the classification taxonomy with reference to taxonomy and the category in the taxonomy, with reference to category.
- translation information about possible translations of the text.
- trans.loc location of the translations.
- translator name of the translator
by Saara Huhmarniemi