
The Speller Error Model
This document describes the different parts of the error model used to create
Makefile configurations
The file tools/spellcheckers/Makefile.mod-desktop-hfst.am looks like
# This is the default weight for all editing operations in the error model: DEFAULT_WEIGHT=10 # Edit distanse for the Levenshtein error model: EDIT_DISTANCE=2 # Define whether we allow changes to the initial letter(s) in the error model, # possible values are: # * no - no longer string edits = only the default, letter-based error model # * txt - use only the txt file as source # * regex - use only the regex file as source # * both - use both the txt and regex files as sources # NB!!! Setting this to anything but 'no' will greatly increase the size and # search space of the error model, and thus make it much, much slower. Make sure # you TEST the resulting error model properly and thoroughly, both for speed # and suggestion quality. INITIAL_EDITS=no # Variable to define whether to enable edits of longer strings (as opposed to # single letters). Possible values are: # * no - no longer string edits = only the default, letter-based error model # * txt - use only the txt file as source # * regex - use only the regex file as source # * both - use both the txt and regex files as sources STRING_EDITS=txt # Variable to specify the edit distance for the regex # version of the strings file. The total edit distance for those operations is # this value multiplied with the value of the DEFAULT_EDIT_DIST variable. STRING_REGEX_EDIT_DISTANCE=2 # Variable to define whether to enable edits of word-final strings (as opposed # to single letters). Possible values are: # * no - no longer string edits = only the default, letter-based error model # * txt - use only the txt file as source # * regex - use only the regex file as source # * both - use both the txt and regex files as sources FINAL_STRING_EDITS=no # Variable to define whether to enable whole-word replacements. Possible values: # - yes # - no WORD_REPLACEMENTS=no
The different options are described above in the comments. In the following
A minimal error model
DEFAULT_WEIGHT=10 EDIT_DISTANCE=2 INITIAL_EDITS=no STRING_EDITS=no FINAL_STRING_EDITS=no WORD_REPLACEMENTS=no
That is, the error model contains only a Levenshtein edit distance 2 error

(Strictly speaking, the error model could have been even simpler, by specifying
The file used to specify the letters of the error model is:
tools/spellcheckers/editdist.default.txt
In that file you specify the whole alphabet used for the error model (that is,
DEFAULT_WEIGHT=10
That is, every letter change is given a default weight of 10 (in addition
One can change this default for individual letters in the alphabet in the
## Inclusions: this is the real alphabet definition: a á 5 b c č 6 ## Transition pairs + weight - section separator: @@ ## Transition pair specifications: a á 4 á a 4
In the above fragment, the letters a, b and c will have a default
Slightly more complex - adding STRING_EDITS
The STRING_EDITS variable governs whether longer stretches than single
- no
- no STRING_EDITS operations
- txt
-
STRING_EDITS taken from a txt file
- regex
-
STRING_EDITS taken from a regex file
- both
- STRING_EDITS taken from both a txt and a regex file
STRING_EDITS=txt
Using a txt file as the input file for STRING_EDITS operations, you edit
gi:giija -2 riikka:rihká -2 rg:rgg -2 rgg:rg -2
The format is:
- input string
- colon
- output string to replace the input string
- TAB
- weight specification (numeric type real)
The intended use is to replace sequences of characters that typically get
The filename for this file is: strings.default.txt. The default part
The string pairs in this file is compiled in as a parallel fst to the
EDIT_DISTANCE=2 STRING_EDITS=txt
we get an error model that can be illustrated as follows:
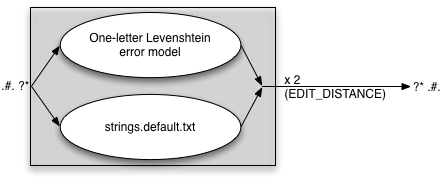
EDIT_DISTANCE=2 means that one can correct up to two errors in the input
STRING_EDITS=regex
The file for the regex string editing model is: strings.default.regex. The
{øø} -> {öö}::0 ,
ø -> {ö}::0 ;
With the Makefile.am variables set as follows:
EDIT_DISTANCE=2 STRING_EDITS=regex STRING_REGEX_EDIT_DISTANCE=2
we get an error model that looks like:
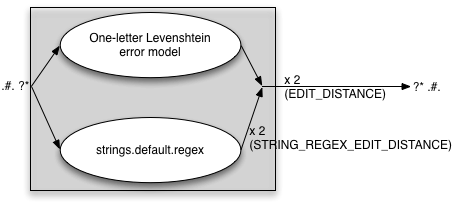
The variable STRING_REGEX_EDIT_DISTANCE regulates how many times the regex
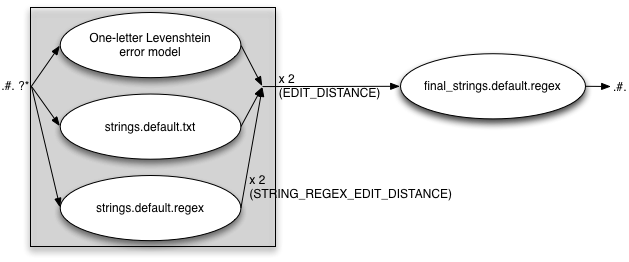
STRING_EDITS=both
In this case both the txt and regex files are included. With the
EDIT_DISTANCE=2 STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2
we get the following error model:
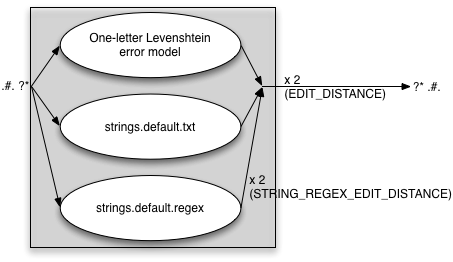
Beware that when using both the txt and the regex strings extensions to the
Increasing the complexity - adding FINAL_STRING_EDITS
This part of the error model is meant to cover errors in suffixes. It comes
The possible values for this variable are the same as for STRING_EDITS:
- no
- no FINAL_STRING_EDITS operations
- txt
-
FINAL_STRING_EDITS taken from a txt file
- regex
-
FINAL_STRING_EDITS taken from a regex file
- both
- FINAL_STRING_EDITS taken from both a txt and a regex file
Each of these values has the same meaning and consequence as for
FINAL_STRING_EDITS=txt
EDIT_DISTANCE=2 STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=txt
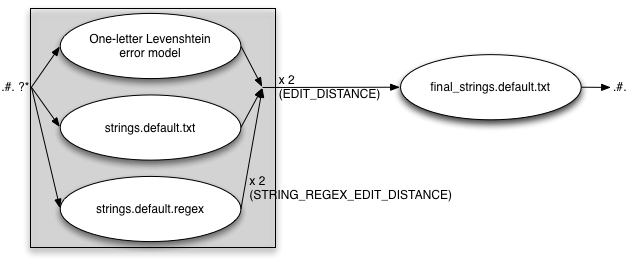
FINAL_STRING_EDITS=regex
EDIT_DISTANCE=2 STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=regex
FINAL_STRING_EDITS=both
EDIT_DISTANCE=2 STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=both
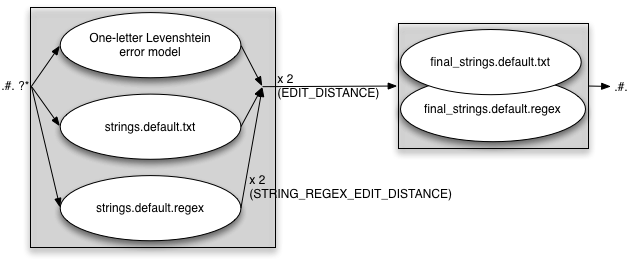
The same warning applies in this case as with the STRING_EDITS — if you use
Maximum complexity - adding INITIAL_EDITS
NB! This is an experimental feature, and is not guaranteed to work as
The purpose of this variable is to allow for special treatment of the initial
Also, as seen below, these edit operations come in addition to the regular
The possible values for the INITIAL_EDITS variable are:
- no
- no INITIAL_EDITS operations
- txt
-
INITIAL_EDITS taken from a txt file
- regex
-
INITIAL_EDITS taken from a regex file
- both
- INITIAL_EDITS taken from both a txt and a regex file
Each of these values has the same meaning and consequence as for
INITIAL_EDITS=txt
EDIT_DISTANCE=2 INITIAL_EDITS=txt STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=both
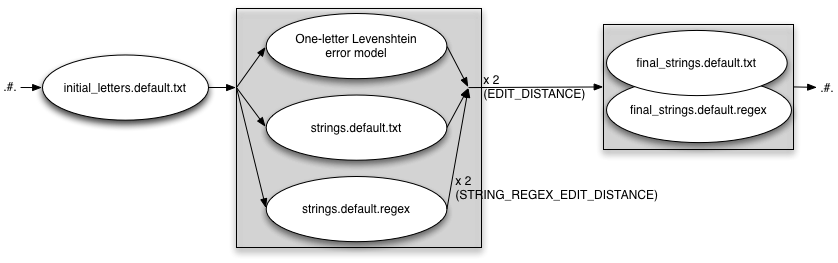
INITIAL_EDITS=regex
EDIT_DISTANCE=2 INITIAL_EDITS=regex STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=both
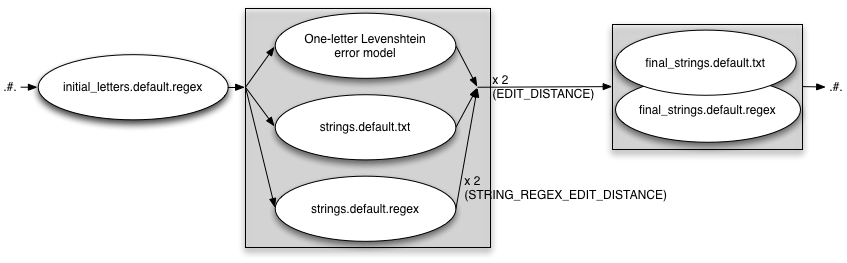
INITIAL_EDITS=both
EDIT_DISTANCE=2 INITIAL_EDITS=both STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=both
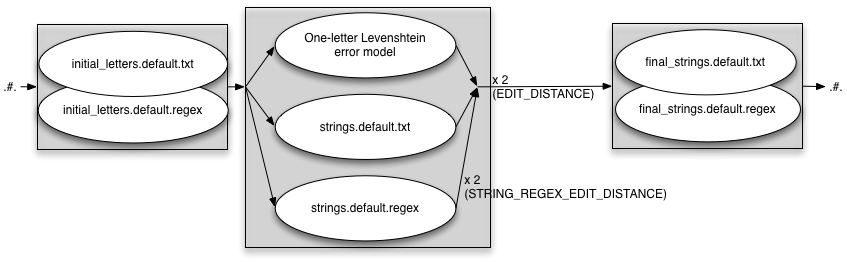
Complete madness - adding WORD_REPLACEMENTS
Actually, that might not be a bad idea. Enabling WORD_REPLACEMENTS does not
oahppiin:ohppiin -10 váiloje:váilo -10 maŋge:mange -10
The format is:
- misspelled word
- colon
- correct word
- TAB
- weight
The possible values for the WORD_REPLACEMENTS variable are:
- no
- no WORD_REPLACEMENTS operations
- yes
- enable WORD_REPLACEMENTS
Expanding on the settings fragment used throughout, we get the following:
EDIT_DISTANCE=2 INITIAL_EDITS=both STRING_EDITS=both STRING_REGEX_EDIT_DISTANCE=2 FINAL_STRING_EDITS=both WORD_REPLACEMENTS=yes
When enabled, the file is compiled into an fst that is applied outside the rest
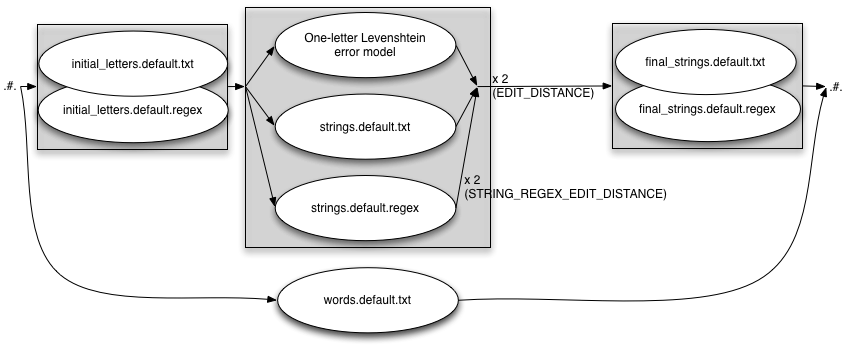
As discussed next, the settings above are not a good idea. The maximum editing
Final words
DO NOT ENABLE EVERYTHING! That will very, very likely make the error model size
The goal of a good speller is to always suggest the correct thing, or something